为什么肿瘤相关试验中记录最后一次访视时间--写给临床试验行业的统计小白
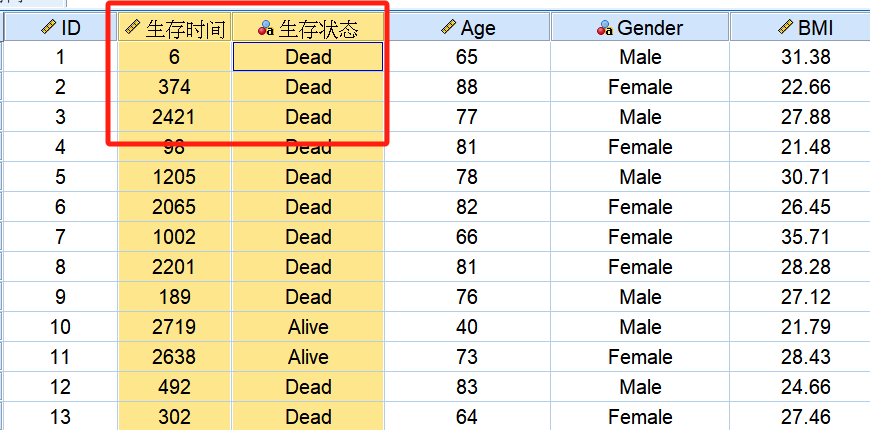
很明显,这篇文章没有任何的技术性可言,写给临床试验行业的统计小白,普及一点生存分析的基本概念和基本常识。OS(overall survival),总生存时间,一般定义为从随机化(也可以是首次用药时间)至死亡的时间长度;这个指标几乎是任何肿瘤相关临床试验中都会采集的数据。所以OS(以及任何其它生存时间)的计算,肯定涉及两个时间点,一个起始时间、一个结局时间。起始时间,只要入组的受试者都会有,如随机化
很明显,这篇文章没有任何的技术性可言,写给临床试验行业的统计小白,普及一点生存分析的基本概念和基本常识。OS(overall survival),总生存时间,一般定义为从随机化(也可以是首次用药时间)至死亡的时间长度;这个指标几乎是任何肿瘤相关临床试验中都会采集的数据。所以OS(以及任何其它生存时间)的计算,肯定涉及两个时间点,一个起始时间、一个结局时间。起始时间,只要入组的受试者都会有,如随机化
样本量计算的目的:在一定检验效能(把握度)基础上,确定研究的最小规模。计算过程1、明确假设(1)明确研究设计类型,如完全随机、配对或随机区组设计;(2)确定研究的主要终点指标,也就是拿研究结果中最重要的那一个指标,作为计算样本量的依据;(3)上述主要终点指标的类型,是计量的还是计数的,是二分类还是多分类,是无序还是无序?2、指定检验水准一般双侧检验(即差异性检验)选定α=0.05,单侧检验α=0.

这个问题本来也没什么可说的,因为将近10年前,导师执笔的专家共识中已经明确:2016年FDA发布的指南当中也有相关的描述,和上述论文中给出的实践标准一致。可是近些年有一些其他作者,也包括一些国外的SCI论文中,对于非劣效临床试验的样本量计算问题,在实际举例时,采用了α=0.05的设定(其实是双侧),这就给人一种错觉,好像我们可以将传统假设检验0.05的水准,原封不动地应用于非劣效试验。对于非劣效的
网上很多文章,讲得过于复杂,甚至有些内容都是错的。这里简单概括下相关分析和回归分析的本质区别:相关分析的两个或多个变量之间,不需要因果关系(可以有也可以无,有的话也无需区分谁是“因”谁是“果”),而回归分析,需要事先确定变量当中谁是“因”谁是“果”,即需要确定的因果关系。另外(感兴趣的可以继续),对于两者的分析结果:相关分析,从变量间数量上共变的关系去阐述结果;而回归分析,是从自变量如何影响应变量
对于数据的正态性检验,方差齐性检验,还有重复测量方差分析中的球形性检验,如果P>0.05,则我们就认为满足正态性、方差齐性和球形性假定(也就是接受了H0),但是,为什么进行差异性检验,P>0.05时我们没有接受H0,即没有作出无差异的推断呢?统计推断就像是法官判案,对于正态性检验、方差齐性检验以及球形性检验,适用了“疑罪从无”的原则,也就是P>0.05时(证据不足)接受了原假设,
为了制作一个方差分析相关的课件,去美国CDC网站下载了几个数据集并进行了整合。过程很简单,记录如下:因为要用到糖化血红蛋白检测结果以及人种、年龄、是否糖尿病患者等数据,所以要下载3个数据集:先进入站点:NHANES Questionnaires, Datasets, and Related Documentation (cdc.gov)选择一个比较近的年份 NHANES 2017-2018:下载列
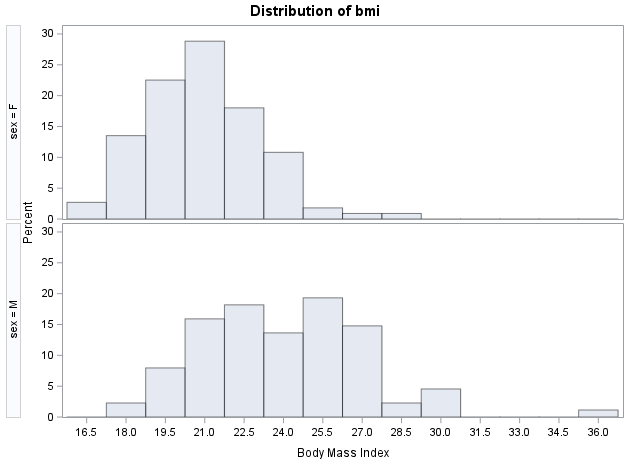
对任何数据的统计分析,都是从统计描述开始的。而数据的分布情况,是统计描述最基本最核心的内容。什么是数据的分布统计上的分布,与位置(location)和频数(frequency)有关;在一个坐标系中,数据在不同位置上往往具有不同的频数,数据的分布就是用来描述这个特征的。比如,男性和女性(某研究中定期进行锻炼的研究对象)的体重指数(计量资料)分布:体重指数(计量资料)分布再比如,在UCLA的演示数据集
任何抽样研究,抽样误差都是不可避免的。当我们抽取了一个样本,如何知道这个样本的特征,就一定是总体特征的真实反映,而不是由于抽样误差导致的假象呢?比如:正常的新生儿,体重平均是6斤半,某医生收集了35例早产儿的体重,平均体重是5斤。那么能不能从他收集的数据,直接得出早产儿的体重,要比足月的新生儿低这个结论呢。能不能下这个结论,最重要的,要解决一个问题:样本中的这30个数据,会不会存在较大的抽样误差,
Fisher's exact test is a statistical significance test used in the analysis of contingency tables. Although in practice it is employed when sample sizes are small, it is valid for all sample sizes.Wit
[细说统计]之-统计基础(2)统计学中的假设检验,是一种基于概率的反证法,我们称之为“小概率反证法”。与数学上的反证法不同,用假设检验的方法证明了的命题,也有可能是错误的。用假设检验的方法,证明小明同学作弊了,需要分三步走:Step 1:明确两个假设(命题),并明确冤枉小明的概率大小H0(无效假设):小明没有作弊H1(备择假设):小明作弊了检验水准:α=0.05(当拒绝H0、接受H1时,犯错的概率